Thread pinning (JDK 21)
OS-thread không gỡ bỏ được Virtual thread khi bị block trong đoạn code có sử dụng từ khóa synchronized
Tuần rồi có một backend service của team trả lỗi 503 cho client, họ xử lý sao đó gây crash, đại loại là một sự cộng hưởng làm sự cố trở nên tệ hơn. Dựa vào incident report, mình đã bắt đầu nghiên cứu, phân tích và có được thông tin ở các phần sau.
Triệu chứng
Tóm tắt các triệu chứng lúc xảy ra incident:
- Application log: lỗi FeignException với nội dung lỗi:
Timeout deadline: 180000 MILLISECONDS, actual: 180005 MILLISECONDS executing... - Trace log: có request thành công (latency rất rất cao), có request 500, service đang nhận số lượng request nhiều hơn lúc bình thường mấy chục lần.
- Client nhận lỗi 503 và gửi log lên Sentry.
- K8S healthcheck thất bại và loại bỏ tất cả các pod ra khỏi service, trả về http status 503 khi nhận request từ client, đây là lý do client nhận status 503 thay vì 500.
Phân tích
Bắt đầu tìm kiếm lỗi cụ thể từ con số trong nội dung lỗi, thì hiểu được thread không lấy được HTTP connection trong pool để thực hiện request đến upstream.
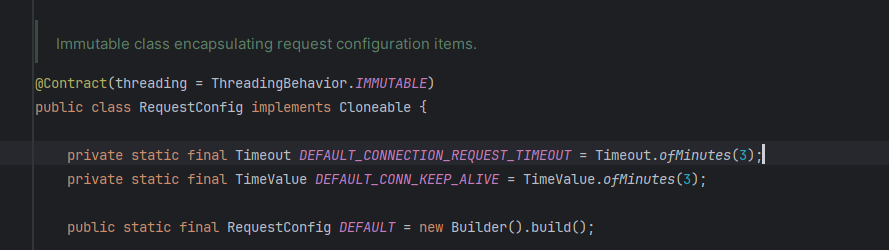
Có 2 điểm cần lưu ý:
- Để tìm kiếm code của thư viện trong Intellij, cần tải source, nếu không thì Intellij sẽ không quét những file jar này.
- Có thể tận dụng AI để search, đặc biệt là khi những con số này được tính toán từ các biến trong code, khó có thể tìm bằng cách thông thường.
3 phút thì lâu thật, tuy nhiên nếu virtual threads (VT) chỉ bị block thì tại sao K8S lại thất bại trong việc thực hiện healthcheck dẫn đến việc nó loại bỏ hết các pod ra khỏi service?
VT bị block thì có thể không tiêu tốn tài nguyên gì, bởi vì nó được thiết kế để làm thế (mà đúng thế thật), ban đầu mình cứ nghĩ như vậy, cơ bản cũng giống ý tưởng của Go, OS-thread sẽ unmount VT đó và xử lý các VT khác, thì healthcheck sẽ thành công.
Đưa thêm dữ kiện này vào AI thì có được câu trả lời, mong muốn là như vậy nhưng JDK 21 có 1 vấn đề: OS-thread (được gọi là carrier thread) không tự unmount được khi đi vào đoạn code có synchronized và bị block ở trong đó (trường hợp này là connection pool bị đầy).
Vậy tiếp theo, upstream service không có lỗi, P99 ~ 400ms, vậy không phải nếu request xong, thì HTTP connection được trả về lại pool hay sao? Lúc đó các VT đang chờ lấy connection sẽ lấy được và thực hiện request, và service sẽ dần trở về bình thường nhanh chóng? Nhưng mà bằng chứng rõ ràng nhất là K8S healthcheck thất bại trong 1 khoảng thời gian dài, chứng tỏ có vấn đề gì đó xảy ra. Cụ thể là việc OS-thread không unmount được dẫn đến service không còn 1 thread nào để có thể làm bất cứ thứ gì, toàn bộ service rơi vào trạng thái đóng băng, chờ hết 180s mới phục hồi, sau đó request lại vào, lại bị đóng băng tiếp.
Nó kiểu như vấn đề vòng lặp, request nhiều gây ra connection pool đầy, OS-thread bị block cùng virtual thread (không unmount được) vì đoạn code lấy connection được đặt trong synchronized, response từ upstream về không có OS-thread để nhận và release connection về pool và rồi pool vẫn cứ đầy.
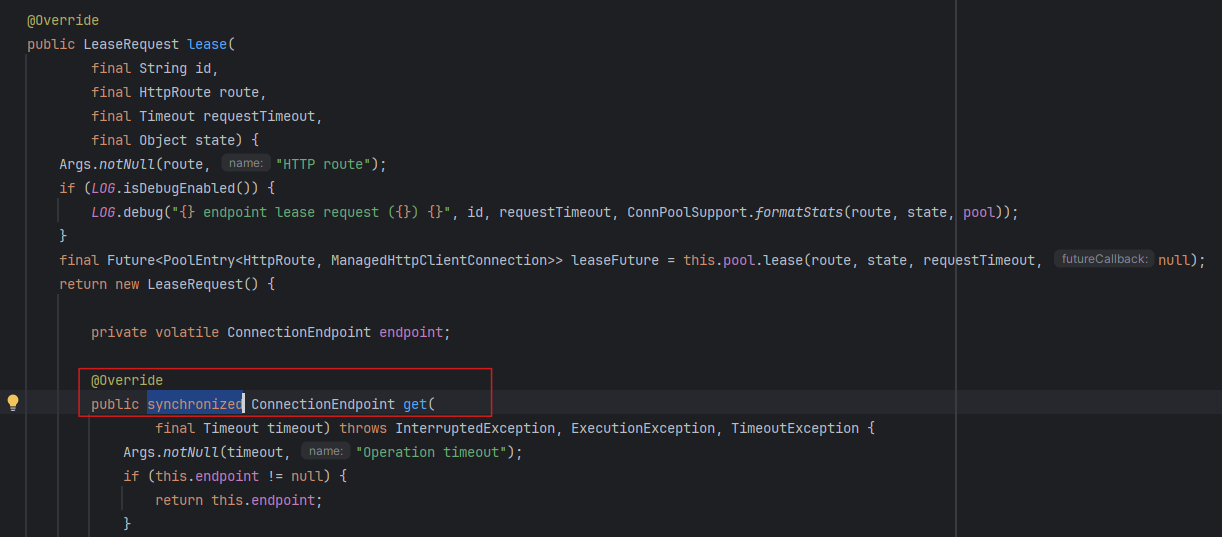
Kiến thức liên quan
Khi khởi chạy ứng dụng Spring có bật virtual thread với JDK 21, số lượng OS-thread mặc định sẽ được cấu hình theo số core cpu, đây là số lượng thread tối đa có thể chạy song song (parallel processing), có thể kiểm chứng bằng lệnh jcmd <pid> Thread.print và tìm các thread có tiền tố ForkJoinPool-1-worker-.
Khi VT bị block và OS-thread không thể unmount, nó có thể sinh ra thêm các OS-thread để bù lại, giá trị tối đa có thể được thiết lập bằng VM option
-Djdk.virtualThreadScheduler.maxPoolSize=<value>
Giải pháp
Giải pháp tạm thời: mục tiêu là hạn chế tối đa việc OS-thread bị block khi lấy HTTP connection từ pool.
- Giảm giá trị timeout của việc lấy connection kết hợp điều chỉnh giá trị healthcheck của K8S.
- Tăng số lượng tối đa của connection pool.
- Tăng giá trị
-Djdk.virtualThreadScheduler.maxPoolSize.
Các cách này đều sẽ có vấn đề khi traffic cao vượt ngoài tầm kiểm soát, nhưng ít nhất không làm toàn bộ service đi bụi.
Giải pháp lâu dài:
- Nâng java version lên 24.
- Hoặc Tắt virtual thread.
Ví dụ minh họa
Virtual thread pinned là một repo mình sử dụng AI để tạo ra để tái hiện vấn đề khi tìm hiểu về incident này, có expose metrics + grafana dashboard để theo dõi trong lúc test. Trong lúc làm repo cũng lượm lặt được thêm vài kiến thức như:
- Có thể tạo các custom threadpool khác để expose metrics, không bị ảnh hưởng khi threadpool chính của chương trình bị block, hoặc chạy trên port khác (mình code các ứng dụng Go sử dụng cách này).
- Có thể xử lý việc instant metric bị sai khi prometheus cào metric theo interval lớn bằng cách đưa ra một metric khác và chỉ lưu lại giá trị lớn nhất theo từng khoảng thời gian.
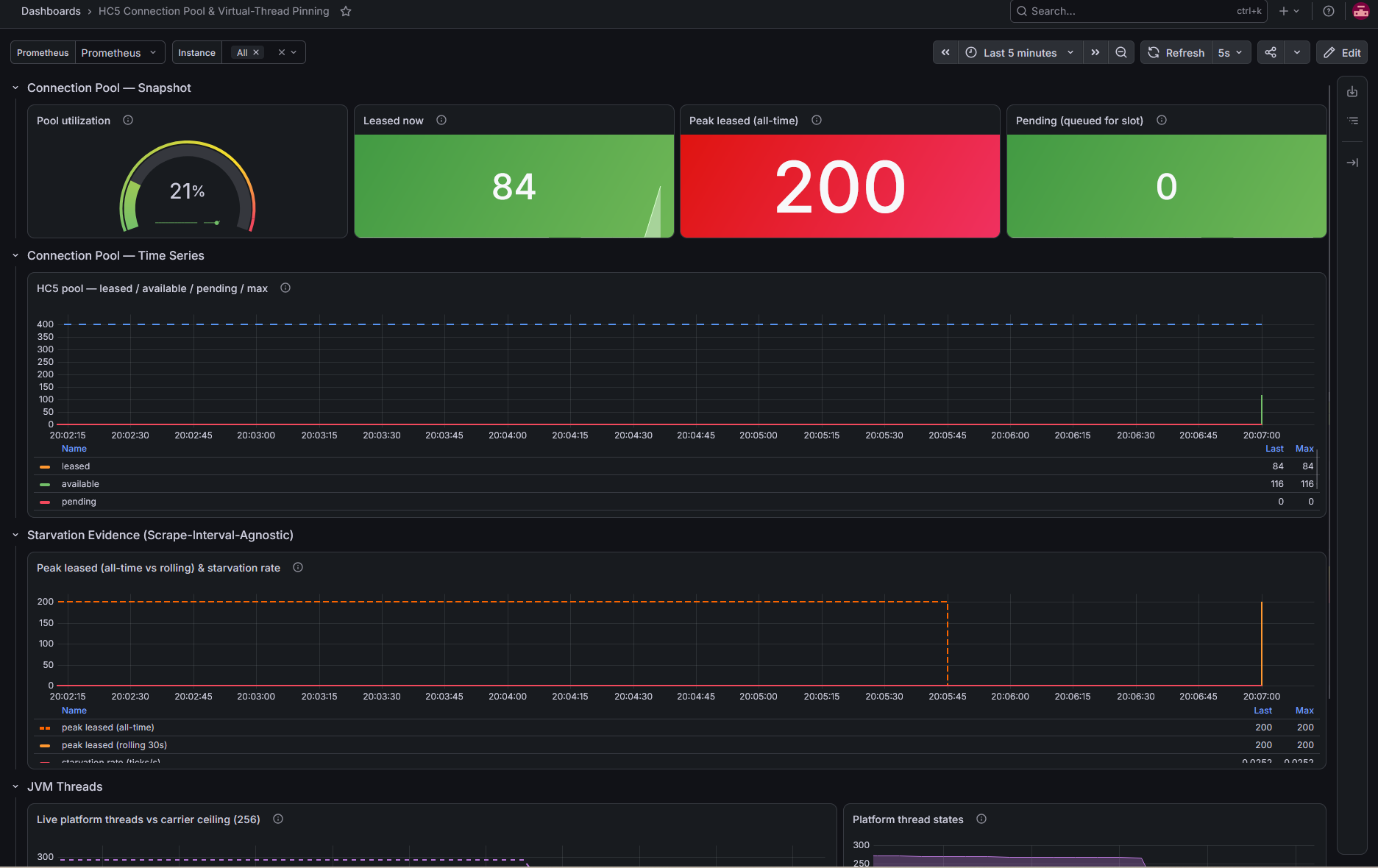
Tổng kết
Mình mất khá lâu để có thể giải đáp được tất cả các thắc mắc từ incident này, phân biệt được đâu là vấn đề thực sự, đâu là vấn đề phát sinh. Biết được vấn đề thực sự mới có được giải pháp đúng.
Và một số kinh nghiệm cần thiết khi điều tra incident khi nó đang xảy ra:
- Bookmark tất cả các link liên quan để theo dõi serice: Grafana, Kibana, Pinpoint, Datadog,...
- Kiểm tra tất cả thông số của service hiện tại, các service liên quan: throughput, latency, error rate, cpu, ram để có thể phán đoán được vấn đề. Lấy ví dụ incident này: upstream có latency p99 400ms, không có lỗi gì, chứng tỏ có vấn đề về việc gửi request từ serivce hiện tại. Nhìn CPU thấp thì đừng loại trừ hệ thống bình thường, bởi vì thực ra không có task nào đang được thực thi, hệ thống bị deadlock.